OpenAI Випустила Два Відкритих Джерела AI Моделі Для Локального Використання, Які Конкурують з Преміум Пропозиціями
Коротко
- OpenAI відкрила два великих мовних моделі під ліцензією Apache 2.0, зламуючи обмеження на ліцензування
- Модель з 120 мільярдами параметрів працює на GPU вартістю $17 000; версія з 20 мільярдами параметрів функціонує на потужних ігрових картах
- Продуктивність конкурує з GPT-4o-mini і o3 – перевершує суперників у математиці, програмуванні та медичних тестах
OpenAI випустила два відкритих мовних моделі в вівторок, які демонструють продуктивність, що відповідає комерційним пропозиціям компанії, і працюють на споживчому апараті – gpt-oss-120b вимагає один GPU обсягом 80 ГБ, а gpt-oss-20b функціонує на пристроях з лише 16 ГБ пам’яті.
Ці моделі, доступні під ліцензією Apache 2.0, досягають рівня продуктивності, близького до o4-mini OpenAI на тестах на логіку. Версія з 120 мільярдами параметрів активує лише 5,1 мільярда параметрів на токен завдяки архітектурі змішування експертів, тоді як модель з 20 мільярдами активує 3,6 мільярда. Обидві моделі витримують контекстні довжини до 128 000 токенів – так само, як GPT-4o.
Реліз під такою специфічною ліцензією є значущою подією. Це означає, що будь-хто може використовувати, модифікувати та заробляти на цих моделях без обмежень. Це стосується всіх, від окремих користувачів до конкурентів OpenAI, таких як китайська стартап-компанія DeepSeek.
Вихід моделей відбувається на фоні зростаючих чуток про наближення GPT-5 і загострення конкуренції в сфері відкритого програмного забезпечення для штучного інтелекту. Ці моделі є останніми відкритими мовними моделями OpenAI з моменту випуску GPT-2 у 2019 році.
Хоча точної дати виходу GPT-5 немає, Сем Алтман натякнув, що це може статися найближчим часом. «У нас є багато нових речей для вас у найближчі кілька днів,» – написав він у своєму твітті, обіцяючи «значне оновлення цього тижня.»
Сьогоднішні відкриті моделі є дуже потужними. «Ці моделі перевершують аналогічні розміри відкриті моделі в логічних завданнях, демонструють сильні можливості використання інструментів та оптимізовані для ефективного розгортання на споживчому апараті,» – заявила OpenAI у своєму оголошенні. Компанія навчила їх, використовувавши підкріплене навчання та техніки, взяті з її o3 і інших фронтонових систем.
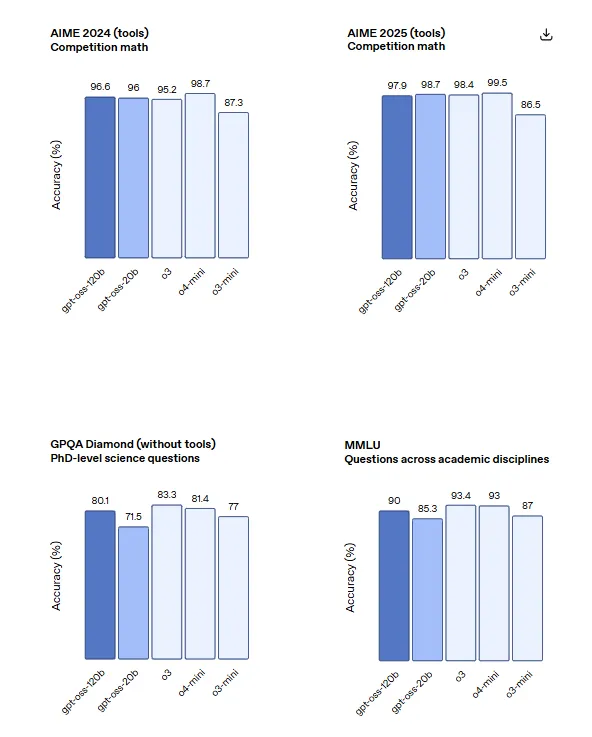
На змаганнях з програмування Codeforces модель gpt-oss-120b отримала рейтинг Elo 2622 з інструментами і 2463 без, перевершивши рейтинг 2719 o4-mini і наближаючись до 2706 o3. Модель показала 96,6% точності на математичних змаганнях AIME 2024 у порівнянні з 87,3% o4-mini та досягла 57,6% на оцінюванні HealthBench, обійшовши 50,1% o3.
Менша модель gpt-oss-20b відповідала або перевищила o3-mini за цими тестами, незважаючи на свій розмір. Вона здобула 2516 Elo на Codeforces з інструментами, досягла 95,2% на AIME 2024 та 42,5% на HealthBench – і все це, витримуючи обмеження пам’яті, що робить її придатною для краю розгортання.
Обидві моделі підтримують три рівні зусиль в логіці – низький, середній і високий, що дозволяє налаштувати затримки для підвищення продуктивності. Розробники можуть змінювати ці налаштування за допомогою однієї фрази в системному повідомленні. Моделі пройшли пост-тренування, використовуючи процеси, схожі на o4-mini, включаючи контрольоване доопрацювання та те, що OpenAI описала як «етап RL з високими обчислювальними витратами.»
Однак не варто вважати, що, оскільки будь-хто може вільно модифікувати ці моделі, це буде просто. OpenAI відфільтрувала певні шкідливі дані, пов’язані з хімічними, біологічними, радіологічними та ядерними загрозами під час попереднього навчання. Етап пост-тренування використовував обдуману алігнментацію та ієрархію інструкцій, щоб навчити відмови від небезпечних запитів та захисту від ин’єкцій запитів.
Іншими словами, OpenAI стверджує, що розробила свої моделі так, щоб вони були настільки безпечними, що не можуть генерувати шкідливі відповіді навіть після модифікацій.
Ерік Уоллес, експерт OpenAI з алігнментації, розкрив, що компанія провела безпрецедентне тестування безпеки перед випуском. «Ми доопрацювали моделі, щоб свідомо максимізувати їхні біологічні та кібер-можливості,» – написав Уоллес у Twitter. Команда курирувала дані, специфічні для доменів з біології, та навчала моделі в середовищах програмування для вирішення завдань з захоплення прапорця.
Версії моделей, які пройшли додаткове налаштування, пройшли оцінювання трьома незалежними експертними групами. «На наших оцінюваннях ризиків, наші зловмисно налаштовані gpt-oss демонструють низьку ефективність порівняно з OpenAI o3, моделлю нижчою за підготовленість,» – зазначив Уоллес. Тестування показало, що навіть з надійним доопрацюванням за допомогою тренувального стеку OpenAI моделі не змогли досягти небезпечного рівня здатності відповідно до рамках підготовленості компанії.
Це означає, що моделі зберігають несупервізоване міркування в ланцюгу думок, що, за словами OpenAI, є вкрай важливим для контролю за AI. «Ми не застосовували жодної прямої супервізії до CoT для жодної моделі gpt-oss,» – заявила компанія. «Ми вважаємо, що це критично для моніторингу неналежної поведінки моделей, обману і зловживання.»
OpenAI приховує повний ланцюг думок у своїх кращих моделях, щоб запобігти конкуренції від повторення їх результатів – а також для уникнення подібної ситуації, яка сталася з DeepSeek, що тепер може статися ще легше.
Ці моделі доступні на Hugginface. Однак, як ми вже зазначали на початку, для запуску версії з 120 мільярдами параметрів вам потрібен потужний GPU з щонайменше 80 ГБ VRAM (наприклад, $17 000 Nvidia A100). Менша модель з 20 мільярдами параметрів вимагатиме щонайменше 16 ГБ VRAM (наприклад, $3 000 Nvidia RTX 4090) на вашому GPU, що є значно, але й не так вже й безкоштовно для апарату споживчого класу.


