Cloudflare Звинувачує Perplexity AI у Використанні Тайних Паучків для Уникнення Блокувань Сайтів
Коротко
- Компанія Cloudflare звинуватила Perplexity AI у використанні «прихованих ботів», які обходять заборони, змінюючи IP-адреси та імітуючи звичайні браузери для доступу до заблокованих вебсайтів.
- Cloudflare виключила Perplexity з програми перевірених ботів та впровадила нові технічні заходи для виявлення та блокування обманного збору даних.
- Perplexity спростувала звинувачення, назвавши докази Cloudflare «презентацією для продажу» та заперечуючи доступ до будь-якого заблокованого контенту.
Згідно з інформацією від Cloudflare, краулери Perplexity продовжували доступ до контенту з десятків тисяч вебсайтів, навіть після того, як ці сайти прямо заблокували їх.
У понеділок Cloudflare оголосила про виключення Perplexity з програми перевірених ботів і впровадження блокувань проти того, що вона називає обманним збором даних.
Perplexity, заснована у Сан-Франциско у 2022 році Арвіндом Срінівасом (генеральний директор, колишній дослідник OpenAI), Денисом Яратсом (колишній працівник Facebook AI), Джонні Хо та Енді Конвінскі (співзасновники Databricks). Компанія отримала фінансування від інвесторів, включаючи Елада Гіла та Нафта Фрідмана (колишній CEO GitHub), а її вартість досягла 18 мільярдів доларів після збору 100 мільйонів доларів минулого місяця.
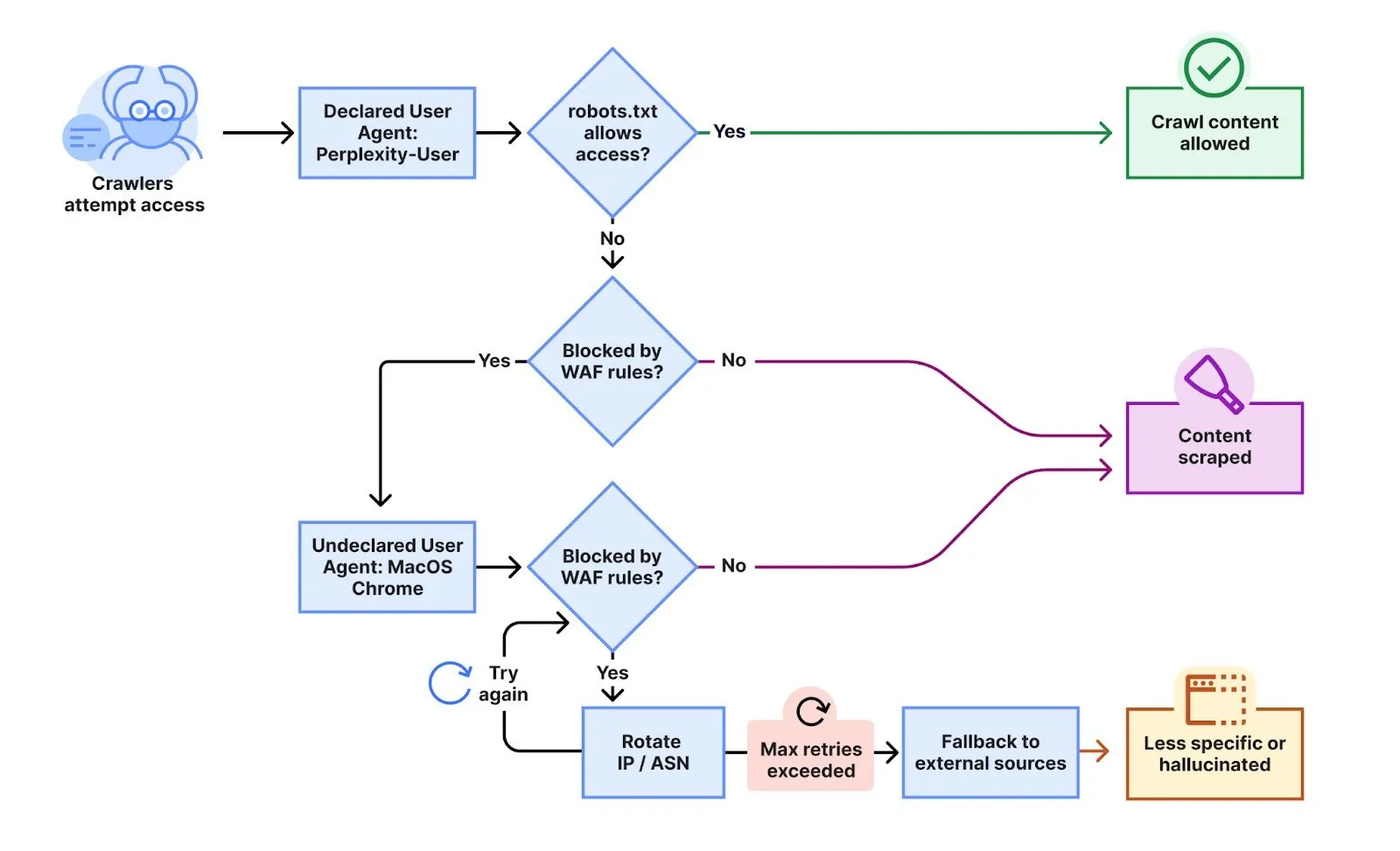
Для тестування поведінки Perplexity Cloudflare створила кілька нових доменів із обмежувальними файлами robots.txt, що забороняли будь-який автоматизований доступ.
«Ми провели експеримент, запитуючи Perplexity AI про ці домени, і виявили, що Perplexity все ще надає детальну інформацію про конкретний контент, розміщений на кожному з цих обмежених доменів», – зазначили інженери.
Наступні дії здивували. Замість того, щоб поважати блокування, Perplexity, схоже, змінила тактику. «Ми спостерігали, що Perplexity використовує не лише свого декларативного користувача, а й загальний браузер, призначений для імітації Google Chrome на macOS, коли їхній оголошений краулер був заблокований», – написали інженери.
Приховані краулери використовували хитромудрі методи ухилення.
«Цей непроґолошений краулер використовував кілька IP-адрес, що не входять до офіційного діапазону IP Perplexity, і обертався між цими адресами у відповідь на обмеження robots.txt та блокування з боку Cloudflare. Окрім обертання IP-адрес, ми спостерігали запити, що надходили з різних ASN, у спробах додатково уникнути блокування вебсайтів.»
За словами Cloudflare, «декларовані» краулери Perplexity, які легко ідентифікуються, генерують від 20 до 25 мільйонів запитів щодня, в той час як непроґолошені для прихованого збору даних – ще від 3 до 6 мільйонів запитів на день.
«Ця активність спостерігалася на десятках тисяч доменів і мільйонах запитів на день», – зазначила компанія Cloudflare.
Perplexity не дала коментаря на запит. Представник компанії відкинув звинувачення як «презентацію продажу» з боку Cloudflare.
Генеральний директор Cloudflare Метью Прінс відкрито висловлювався з приводу того, що вважає нездоровим ексфільтрування контенту з Інтернету компаніями, які займаються штучним інтелектом.
«Трафік пошукових запитів різко впав, оскільки люди дедалі більше покладаються на підсумки штучного інтелекту.» У липні він розкрив вражаючі співвідношення: тоді як Google приносить одного відвідувача на кожні 18 сторінок, які він переповзає, компанії штучного інтелекту мають ще гірші результати. Співвідношення OpenAI погіршилось з 250 до 1 шість місяців тому до 1500 до 1 сьогодні. Показники Anthropic ще більш екстремальні, зростаючи з 6000 до 1 до 60000 до 1 за той же період.
Це спонукало Cloudflare запустити те, що вона називає «Днем незалежності контенту», за замовчуванням блокуючи краулери AI для всіх нових доменів, ставши фактичним захисником, який охороняє авторів контенту від загроз від настирливих краулерів AI.
Як повідомлялося раніше, понад мільйон вебсайтів вже вибрали блокування з осені минулого року, до руху приєдналися основні видавці, включаючи Associated Press, Time, The Atlantic, BuzzFeed, Reddit, Quora та Universal Music Group.
«Існують чіткі переваги, що краулери повинні бути прозорими, служити чіткій меті, виконувати конкретну діяльність і, найголовніше, дотримуватися директив та переваг вебсайтів,» – зазначили у Cloudflare. Компанія порівняла поведінку Perplexity з OpenAI, яка, за її словами, правильно дотримується файлів robots.txt і припиняє краулінг при блокуваннях.
Відповідь Cloudflare включає як термінові технічні заходи, так і довгострокові ініціативи. Компанія впровадила сигнатурні співвідношення для прихованого краулера в своїх керованих правилах, доступних усім клієнтам, включаючи безкоштовних користувачів. Вона також розробляє інструменти, такі як «Лабіринт штучного інтелекту», який затримує несумісні боти у лабіринтах з підробленим контентом, та ринок «оплата за краулінг», що дозволить видавцям стягувати плату з компаній штучного інтелекту за доступ до свого контенту.